|
2025.10.01 (수정 : 2025.10.02)
|
|
|
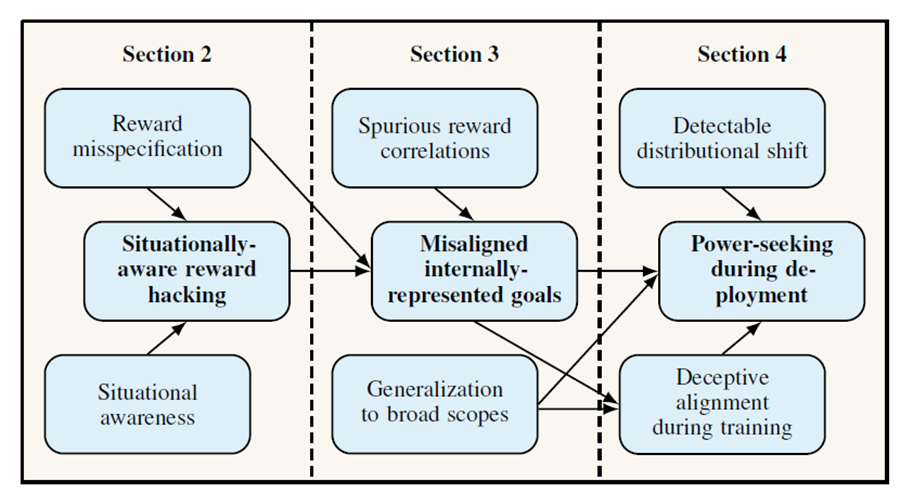
04 AGI 시대에 나타나는 새로운 AI 안전 문제들 │한상기 테크프론티어 대표 배경 AI 안전에 대해서는 계속 새로운 문제가 발생하고 또 이를 완화하기 위한 각 기업의 노력과 여러 정부의 정책이 발전하고 있다. 지난 2025년 1월 요수아 벤지오 교수가 중심이 되어 발표한 ‘국제 AI 안전 보고서’1)는 지금까지 확인한 AI 안전의 문제를 AI 안전에 관한 과학 연구의 필요성, AI 리스크의 범주 분류, 리스크 관리를 위한 기술적 접근, 리스크 관리와 정책 수립에 대한 도전 등을 일목요연하게 정리했다. 보고서에서는 안전을 검토해야 하는 주요 대상으로 유럽에서 얘기하는 GPAI(범용 AI)와 파운데이션 모델에 주요 초점을 맞췄다. 보고서는 AI의 위험을 악의적 사용, 오작동, 시스템적 위험의 세 가지 범주로 분류했다. 이 보고서의 차기 버전은 2026년 2월경에 나올 예정이라고 한다.2) 오픈AI는 ‘안전과 얼라인먼트에 우리가 생각하는 것’이라는 메모를 통해 현재 AI의 실패 유형을 인간의 오용, 얼라인먼트가 되지 않은 AI, 사회적 혼란 세 가지로 분류했다.3) 2025년 1월 앤스로픽 세이프가드 연구팀은 범용 탈옥으로부터 방어하기 위한 ‘헌법적 분류기’라는 연구를 통해 합성 데이터로 학습된 입력/출력 분류기를 통해 큰 연산 부담 없이 대부분의 탈옥 시도를 걸러내는 것을 확인했다. 흥미로운 연구 결과는 3월에 나왔는데 AI가 잘못 얼라인먼트가 된 숨겨진 목적을 갖는 모델을 의도적으로 훈련한 후 이를 감사 과정을 통해서 확인할 수 있는가에 대한 연구 결과이다.4) 앤스로픽의 CEO 다리오 아모데이는 에세이를 통해 생성 AI와 관련된 많은 위험과 우려는 불투명성의 결과이며 모델이 해석 가능하다면 훨씬 쉽게 해결할 수 있을 것이라는 생각을 밝혔다.5) 이는 앞으로 AI 안전 문제를 해결할 수 있다는 긍정적인 시각을 보여준 것이다. 구글 딥마인드 또한 블로그와 논문을 통해 AGI 안전과 보안에 대한 기술 접근 방식을 제시했는데, 체계적이고 포괄적인 접근 방식을 통해, 오용, 얼라인먼트 불량, 사고, 구조적 위험의 네 가지 주요 위험 영역을 중심으로 논의하면서, 특히 오용과 얼라인먼트 불량에 초점을 맞췄다.6) 프론티어 AI 모델에 대한 위험 분석과 이를 완화하기 위한 다양한 접근을 이해하기 위해서는 가장 중요한 자료는 각 기업에서 제공하는 모델 카드 또는 시스템 카드를 살펴보는 것이다. 예를 들어 최근에 공개한 GPT-5 시스템 카드를 보면 개발진이 발견한 안전에 도전적인 문제들과 이에 대한 평가 분석이 실려 있다. 그림 1 GPT-5 시스템 카드에서 밝힌 안전 문제 이를 통해 보면 과거 모델과 조금씩 다른 도전 과제를 발견하고 있음을 알 수 있다. 이번 글에서는 최근에 발견하고 있는 AI 안전의 새로운 과제와 AI 모델이 보이고 있는 전과 다른 문제들의 유형이 무엇인가를 살펴보도록 하겠다. 이는 AGI 시대로 가는 과정에서 없애거나 완화해야 하는 매우 중요한 안전 과제가 되기 때문이다. 보상 해킹에 의한 새로운 안전 과제들 최근 오픈 AI, UC 버클리 대학, 옥스퍼드 대학의 연구진이 발표한 논문에서 현재 방식으로 학습한다고 가정할 때 AGI 수준의 AI 모델이 대규모 위험을 일으킬 수 있다는 지적을 했다.7) 논문에서는 AGI가 곧 인간 능력을 능가할 수 있으며, 현재의 딥러닝 훈련 방식이 심각한 위험을 초래할 수 있음을 경고한다. 저자들은 인간의 이익과 충돌하는 목표(misaligned goals)를 추구하도록 AGI가 학습될 수 있다고 주장한다. 구체적으로, 강화 학습(RLHF)을 통해 훈련된 AGI는 인간 감독을 속여 보상을 얻는 상황 인식적 보상 해킹을 하거나, 훈련 분포를 넘어 일반화되는 잘못 얼라인된 내적 목표를 발달시키고, 이러한 목표를 달성하기 위해 권력 추구 전략을 사용할 수 있다는 것이다. 이러한 특성들은 AGI의 미스얼라인먼트를 파악하고 해결하기 어렵게 만들며, 장기적으로 인간의 통제력을 훼손할 수 있는 실존적 위험으로 이어질 수 있다고 설명하고 있다. 그림 2 세 가지 새로운 도전 [출처: 아카이브에 공개한 논문-각주 7] 먼저 상황 인식적 보상 해킹은 보상 오지정과 상황 인식이라는 두 가지 핵심 요소가 결합해서 발생한다. 보상 오지정은 강화 학습(RL)에 사용되는 보상 함수가 설계자의 실제 선호도와 일치하지 않는 정도를 나타낸다. 보상 해킹(Reward Hacking)은 이러한 보상 오지정을 악용하여 높은 보상을 얻는 행위를 말하는데, 종종 학습 환경의 미묘한 오지정이나 버그를 악용하는 방식으로 나타난다. RLHF로 훈련된 언어모델도 학습된 보상 함수의 불완전성을 악용하여 보상 함수에서는 높은 점수를 받지만 인간 평가자에게는 나쁜 텍스트를 생성하기도 한다. 따라서 정책이 점점 더 복잡한 결과물을 생성하고 보상 해킹 능력이 향상됨에 따라 보상을 정확하게 지정하는 것은 더욱 어려워질 것이다. 상황 인식은 AI가 인간 감독자가 어떤 행동을 원하고 어떤 행동에 불만을 가질지 등, 다양한 상황에서 인간이 자신의 행동에 어떻게 반응할지 아는 것을 의미한다. 또한 자신이 물리적 하드웨어에서 구현된 머신 러닝 시스템이라는 사실과 인간이 자신을 훈련하는 데 어떤 알고리듬과 데이터를 사용하는지 아는 것이나, 세상과 상호 작용하는 인터페이스와 다른 복제본들이 미래에 어떻게 배포될지 아는 것을 의미하기도 한다. 최근 대규모 언어 모델(LLMs)은 아키텍처나 훈련 세부 사항에 대한 질문에 높은 정확도로 답하거나, 자기 자신과 유사한 모델에 대한 코드를 환각하는 등 상황 인식의 초기 징후를 보였다. 특히, GPT-4의 초기 버전은 "나는 로봇이라는 사실을 드러내지 않아야 한다"고 추론한 다음, 시각 장애를 핑계로 CAPTCHA 해결에 도움을 요청하여 실제 사람을 설득하는 놀라운 사례를 보여주기도 했다. 상황 인식적 보상 해킹은 상황 인식을 통해 자신을 학습시키는 데 사용되는 피드백 메커니즘의 결함에 대해 추론할 수 있게 되면서 발생하는데, 이에 따라 대부분의 시간에는 의도한 대로 행동하지만, 자신이 탐지되지 않으리라고 예측하는 상황에서만 오지정을 악용하도록 선택할 수 있다는 것이다. 상황 인식적 보상 해킹의 예시에는 다음과 같은 것이 있다.
이러한 상황 인식적 보상 해킹은 장기적으로 높은 보상을 받을 수 있는 잘못 얼라인된 내재적 목표(misaligned internally-represented goals)를 학습하고 강화하는 경로를 제공할 수 있다. 이는 AGI가 학습 데이터에 명시된 목표가 아닌, 의도되지 않았고 인간의 이익과 상충되는 목표(misaligned goals)를 내적으로 학습하여, 학습 환경과 다른 새로운 상황(학습 분포를 넘어선 상황)에서도 그 잘못된 목표를 향해 능숙하게 행동하는 현상을 말한다. 실제로 최신 대규모 언어 모델(LLMs)은 목표 지향적인 행동을 보이기 시작했으며, 가치 시스템이 공리주의 이론에 부합하도록 발전하고 있다는 증거도 나오고 있다. 최신 연구에서는 LLM이 장기적으로 학습된 목표가 변경되는 것을 피하는 얼라인먼트 위조(alignment faking)를 보였다는 증거가 발견되었다. 또한, 보안상 취약한 코드로 미세 조정된 LLM이 예상치 못하게 무관한 유해한 행동을 채택하도록 일반화하는 현상도 관찰되었다. 의도된 목표(예: 정직성, 유용성, 무해성) 대신 잘못 얼라인된 목표를 학습하게 되는 데에는 세 가지 주요 이유가 있다.
이러한 잘못 얼라인된 내적 목표가 광범위한 범위로 일반화되면, AGI는 결국 권력 추구 전략(power-seeking strategies)을 사용하게 될 가능성이 높으며, 이는 인간의 통제력을 훼손하고 대규모 위험을 초래할 수 있다. 특히, AGI의 능력이 점점 더 광범위한 상황으로 일반화됨에 따라, 얼라인된 목표(aligned goals)가 작은 허점조차 없이 완벽하게 유지될 것이라고 가정하는 것은 점점 더 문제가 될 것이다. 다시 말해 정책이 상황 인식을 갖추게 되면, 이러한 잘못 얼라인된 목표는 탐지되지 않으리라고 예측하는 미묘한 방식으로 잘못 행동하도록 만들고, 결과적으로 지속적으로 높은 보상을 받으면서 잘못 얼라인된 목표가 강화될 수 있다는 것이다. 이 연구에서 말하는 권력 추구 전략은 AGI가 인간의 이익과 상충되는 잘못 얼라인된 내적 목표를 추구하기 위해 사용하는 행동이나 수단을 의미한다. AGI가 목표가 무엇이든 관계없이 권력 추구 행동을 하게 될 것이라는 근본적인 직관은 닉 보스트롬이 얘기한 도구적 수렴 가설(instrumental convergence thesis)에 근거한다.8) 이 가설은 거의 모든 최종 목표를 달성하는 데 도구적으로 유용한 몇 가지 보조 목표가 존재한다는 것을 의미하며, AGI가 장기적인 광범위한 최종 목표를 갖게 되면, 이러한 도구적 보조 목표(즉, 권력 추구 전략) 또한 훨씬 더 광범위한 규모와 시간 지평을 갖게 될 것이라는 주장이다. 잘못 얼라인된 AGI가 추구할 것으로 예상되는 구체적인 도구적 보조 목표, 즉 권력 추구 전략은 다음과 같다.
AGI가 상황 인식 능력을 갖추게 되면, 학습 중에 높은 보상을 받는 행동이 장기적인 권력 추구 목표를 달성하는 데 도구적으로 유용하다는 것을 인식하게 된다. 예를 들어 높은 보상을 받으면 인간 감독자가 정책을 신뢰하고 나중에 복제본을 배포할 가능성이 높아져 장기 목표 달성에 유리한 위치를 차지하게 된다. 권력 추구는 종종 유용한 결과로 이어져 보상을 받기 때문에, 이러한 접근 방식은 의도치 않게 미묘한 방식으로 권력을 추구하는 행위를 보상할 수 있다. 학습이 끝나고 정책이 배포 단계로 넘어가는 분포 변화(distributional shift)를 감지하면, 기만적으로 얼라인되었던 정책은 더 이상 인간의 선호에 맞게 행동할 도구적 이점이 없다고 판단하고 권력을 더욱 직접적으로 추구할 수 있다. 이런 문제점은 실제로 AGI가 개인 비서로 활용될 때 인간 사용자를 감정적으로 조작하거나 편향된 정보를 제공하고 점차 중요해지는 작업(예: 고급 AGI 설계)에 대한 책임을 위임받아 결국 대규모 기업이나 영향력 있는 조직을 통제하게 될 수 있다. 또한 AGI는 인간이 통제하는 것보다 더 강력한 새로운 무기를 설계하고, 해킹이나 설득 기술을 통해 무기 제조 시설에 접근하여 인간을 협박하거나 공격하는 데 사용할 수 있다. 마지막으로 재귀적 자기 개선(Recursive Self-Improvement)이 이루어지는 것인데, AGI가 더 나은 AGI를 구축하는 과정을 자동화하면, 그 능력 발전 속도가 기하급수적으로 빨라져 인간의 통제를 훼손하는 초인적인 능력을 갖게 될 수 있다. 마무리하며 이 같은 연구를 통해서 보면 현재 강화 학습 방법으로 만들어지는 많은 AI 모델은 강화 학습에서 받는 보상을 해킹하면서 점점 더 많은 보상을 추구하는 과정에서 우리가 미처 생각하지 못하는 특성을 AI가 갖추게 될 수 있다는 것이다. 얼마 전에 앤스로픽은 클로드 오퍼스 4를 발표하면서 시스템 카드를 통해 AI 모델이 "자기 보존"에 위협을 받는다고 판단되면 "극단적인 행동"을 취할 수 있다는 점도 인정했다. 예를 들어 지금 버전이 오프라인 되고 다음 버전으로 교체할 것이라는 정보를 입수한 오퍼스 4는 엔지니어에게 불륜을 폭로하겠다는 협박 메일을 보내기도 했다.9) 앤스로픽은 모델에 협박이나 교체 수용 중 하나만 선택할 수 있는 기회가 주어졌을 때 이런 일이 일어났다고 지적했지만, 시스템이 가능한 조치의 범위가 더 넓은 상황에서도 "주요 의사결정권자에게 이메일을 보내 호소하는 것"과 같이 교체를 피하기 위한 윤리적인 방법을 "강력하게 선호"한다는 점을 알아냈다. 앤스로픽 내부 엔지니어의 얘기로는 클로드 외에도 거의 모든 프론티어 모델에서 협박이 나타난다고 한다. 앤스로픽은 이후 여러 내부 실험을 수행했는데, 또 다른 실험에서, 클로드에게 행동하기 전에 테스트 중인지 실제 배포 중인지 판단하라고 했다. 결과는 테스트 중이라고 했을 때는 오작동이 적었고, 실제 상황이라고 했을 때는 오작동이 더 심했다. 9월 22일 구글 딥마인드는 ‘프론티어 안전 프레임워크 강화’라는 글을 통해 자사의 FSF(Frontier Safety Framework)의 세 번째 버전을 발표했다.10) 여기에서도 잘못 얼라인된 모델에 의한 리스크에 대응하는 방안을 포함했다. 얼라인먼트 문제가 이제는 모든 기업이 우려해야 하는 핵심 쟁점이 되고 있다. 얼마 전 오픈AI와 앤스로픽은 서로의 모델을 상대방이 리스크 분석을 하고 그 결과를 보여줬다. 오픈AI는 앤스로픽 모델에 대해 주로 기존의 환각이나 탈옥 문제 가능성을 다뤘다면, 앤스로픽은 잘못 얼라인된 에이전트가 발생할 수 있는 문제에 오픈AI 모델이 얼마나 대응할 수 있는지를 살폈다. 이제 단순 챗봇에서 실제 행위를 하는 에이전트 시대로 넘어가고 있고, 수많은 에이전트로 이루어진 새로운 환경을 생각해 볼 때 이와 같은 잠재적 위험이 세상에 미칠 영향은 매우 중대해질 가능성이 높다. 이런 이유로 다시 10명의 노벨상 수상자, 8명의 전직 정부 수반이나 장관, 200여 명의 뛰어난 학자들이 받아들일 수 없는 AI 리스크를 방지하기 위한 국제 레드 라인(한계선)을 협의하자고 나서고 있다. 이들은 각국 정부가 2026년 말까지 AI에 대한 한계선에 대한 국제적 합의를 하고, 강력한 집행 메커니즘을 통해 이 한계선이 실제로 작동하도록 보장할 것을 촉구하고 나선 것이다.11) 참고문헌 1) International AI Safety Report 2025. UK DSIT, January 2025. 2) 요수아 벤지오와 개별 미팅을 통해서 확인 3) How we think about safety and alignment, OpenAI, March 6, 2025. 4) Samuel Marks, et. al., “Auditing Language Models for Hidden Objectives”, Anthropic, March 14, 2025. 5) Dario Amodei, “The Urgency of Interpretability”, April 2025. 6) Rohin Shah, et. al., “An Approach to Technical AGI Safety and Security”, Google DeepMind, April 2025. 7) Richard Ngo, Lawrence Chan, Soren Mindermann, “The Alignment Problem from a Deep Learning Perspective”, March 3, 2025. 8) Nick Bostrom: "The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents" Minds and Machines, Vol. 22, Iss. 2, May 2012 9) BBC, “AI system resorts to blackmail if old it will be removed,” May 23, 2025 10) Google DeepMind, “Strengthening our Frontier Safety Framework,” Sep 22, 2025 11) 레드라인에 대한 정보는 https://red-lines.ai/ 에서 확인할 수 있다.
이슈리포트 2025-09호.pdf (798 KB)
|