|
2026.01.29 (수정 : 2026.02.02)
|
||
|
01 피지컬 AI를 위한 플랫폼 현황 (파트 1) │한상기 테크프론티어 대표
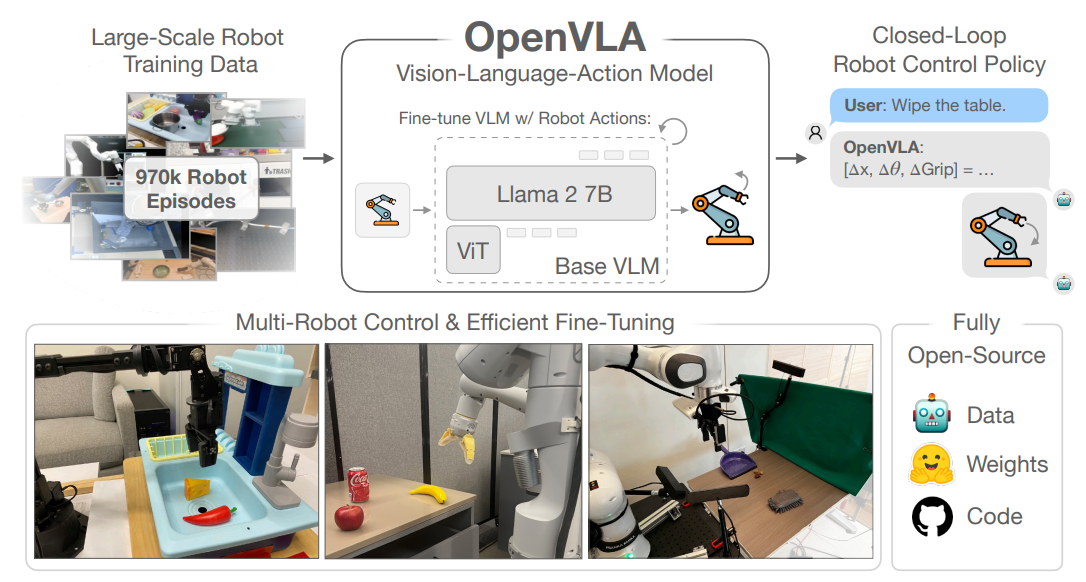
피지컬 AI는 향후 우리나라 AI 전략의 핵심이 될 것이라고 하며, 피지컬 AI 분야에서 세계 1위 국가가 되자는 목표를 발표했다. 지난 CES에서도 가장 중심 화두는 피지컬 AI였으며 이는 젠슨 황 엔비디아 CEO가 작년부터 강조한 주제이기도 하다. 엔비디아와 국내 주요 기업 간의 전략적 협업은 피지컬 AI를 중심으로 이루어지고 있으며, 그에 따라 정부를 포함해 26만 장의 첨단 GPU 우선 공급의 협력이 이루어지기도 했다. UAE와는 항만을 위한 피지컬 AI 협력이 추진되고 있으며, 정부는 "대한민국은 세계 최고 수준의 제조 현장과 산업 데이터, 반도체 배터리, 모빌리티 로봇 등 피지컬 AI에 최적화된 산업 구조, 빠른 융합과 고도화가 가능한 연구·인재 역량을 갖추고 있다"라고 밝히기도 했다. 그런 차원에서 피지컬 AI 연구를 위해 핵심으로 등장한 VLA (비전-언어-행동) 모델의 발전 현황과 물리적 세계를 위한 월드 모델, 나아가 월드 파운데이션 모델 개발, 그리고 엔비디아, 테슬라, 구글이 이 분야에 어떻게 접근하고 있는가를 살펴보는 것이 중요하다. 각 기업이 최종적으로 원하는 것이 물리적 세계에서 실체를 갖는 휴머노이드 로봇, 자율 주행차, 공장이나 항만 같은 산업 시설 등을 자동화, 자율화할 수 있는 AI 기술이지만, 각각 접근하는 철학과 미래 비전이 다르기 때문에 이에 대한 좀 더 명확한 이해가 필요하다고 생각한다. 일단 이번 달에는 첫 번째로 VLA 모델의 발전 과정을 살펴보기로 한다. VLA 모델은 무엇인가? VLA는 비전 언어 액션 모델의 약자로 시각 입력(Vision)과 언어 입력(Language)을 공동으로 해석하여, 물리적 세계에서 실행 가능한 행동(Action)을 직접 산출하도록 설계된 엔드투엔드 멀티모달 정책 모델을 말한다. 즉, “보는 것–이해하는 것–움직이는 것”을 하나의 정책 함수로 통합한 구조이다. 이를 통해 심볼릭 중간 표현을 제거하고 자연어 명령의 직접적인 행동 조건화와 새로운 태스크에 대한 제로 샷이나 퓨 샷을 일반화한다. 이는 다음에 설명할 월드 모델의 약식 구현이라고 볼 수 있다. VLA 모델은 단순 로봇 제어 기술이 아니라 LLM을 물리 세계로 확장하고, 디지털 AI와 현실 세계를 연결하는 실행 계층이다. 다시 말해 피지컬 AI를 프로그래밍 가능한 기계에서 지시로 움직이는 지능체로 전환하기 위한 핵심 아키텍처이다. 초기 모델로는 여러 종류의 로봇 데이터를 한 모델 안으로 통합해 학습하는 방식의 옥토(Octo)와 행동 토큰화 개념을 오픈소스 모델에 이식 (사실상의 표준 기법), 로봇의 행동을 어떻게 표현하고 어떤 방식으로 LLM과 결합하는 것이 최적인가를 고민한 UC 버클리, 스탠퍼드, MIT 등 여러 대학과 피지컬 인텔리전스, 구글 딥마인드가 공개한 오픈VLA가 있다.1) 옥토는 구글 딥마인드가 공개한 범용 로봇 정책(Generalist Robot Policy) 계열 모델로, 서로 다른 로봇·센서·태스크 데이터를 하나의 정책 공간으로 통합해 멀티태스크·멀티로봇 제어를 목표로 한다. 다양한 로봇에서 수집된 시각·언어·행동 데이터를 공통 표현으로 정규화하여 학습한, 엔드투엔드 VLA 정책 파운데이션 모델이라고 할 수 있다. 옥토의 가장 큰 기여는 로봇마다 다른 액션 공간을 공통 표현으로 정규화한 점이다. 이를 통해 하나의 정책이 여러 로봇에서 작동하게 하고, “로봇마다 모델을 다시 학습”할 필요를 감소시켰다. 어떻게 보면 옥토는 로봇판 GPT 이전 단계에 해당한다고 볼 수 있다. 옥토는 VLA 모델의 스케일 법칙 가능성을 입증했고, 멀티 로봇 데이터 연합 학습의 실증을 보여줬다. 오픈 VLA는 기존의 VLA 모델들이 갖고 있던 한계를 넘어서기 위한 노력이다. 기존 모델은 대규모 데이터와 인프라가 폐쇄적이고, 학습 파이프라인과 설계 선택이 불투명했으며, 연구 커뮤니티가 정책 스케일링을 실험하기 어려웠다. 오픈 VLA는 이러한 상황에 대한 의도적인 반대 방향의 설계로, VLA를 연구 가능한 파운데이션 모델로 공개한다는 목적을 갖고 있었다. 모델 구조, 학습 방식, 체크 포인트를 공개하고, 특정 기업 인프라에 의존하지 않아 재현 가능성을 보였으며, 데이터와 모델 스케일 변화에 따른 성능 법칙이 가능한지 탐구하는 연구였다. 시각–언어 얼라인먼트를 인식이나 캡션 생성이 아니라 행동 생성의 전제 조건으로 사용한다. 즉 언어를 설명이 아닌 행동 조건으로 취급하는 것이다. 오픈 VLA는 세 가지 블록으로 구성한다. ViT 계열의 비전 인코더, 트랜스포머 기반 LLM으로 만든 언어 인코더, 멀티 모달 퓨전 프랜스포머이다. 특히 멀티 모달 퓨전 트랜스포머는 ‘이 상황에서, 이 지시를 받았을 때, 어떤 행동이 가능한가’라는 질문에 답하는 행동 조건화 추론기이다. 마지막이 연속 제어 값을 출력하는 액션 헤드로 저수준 제어기로 직접 전달한다.
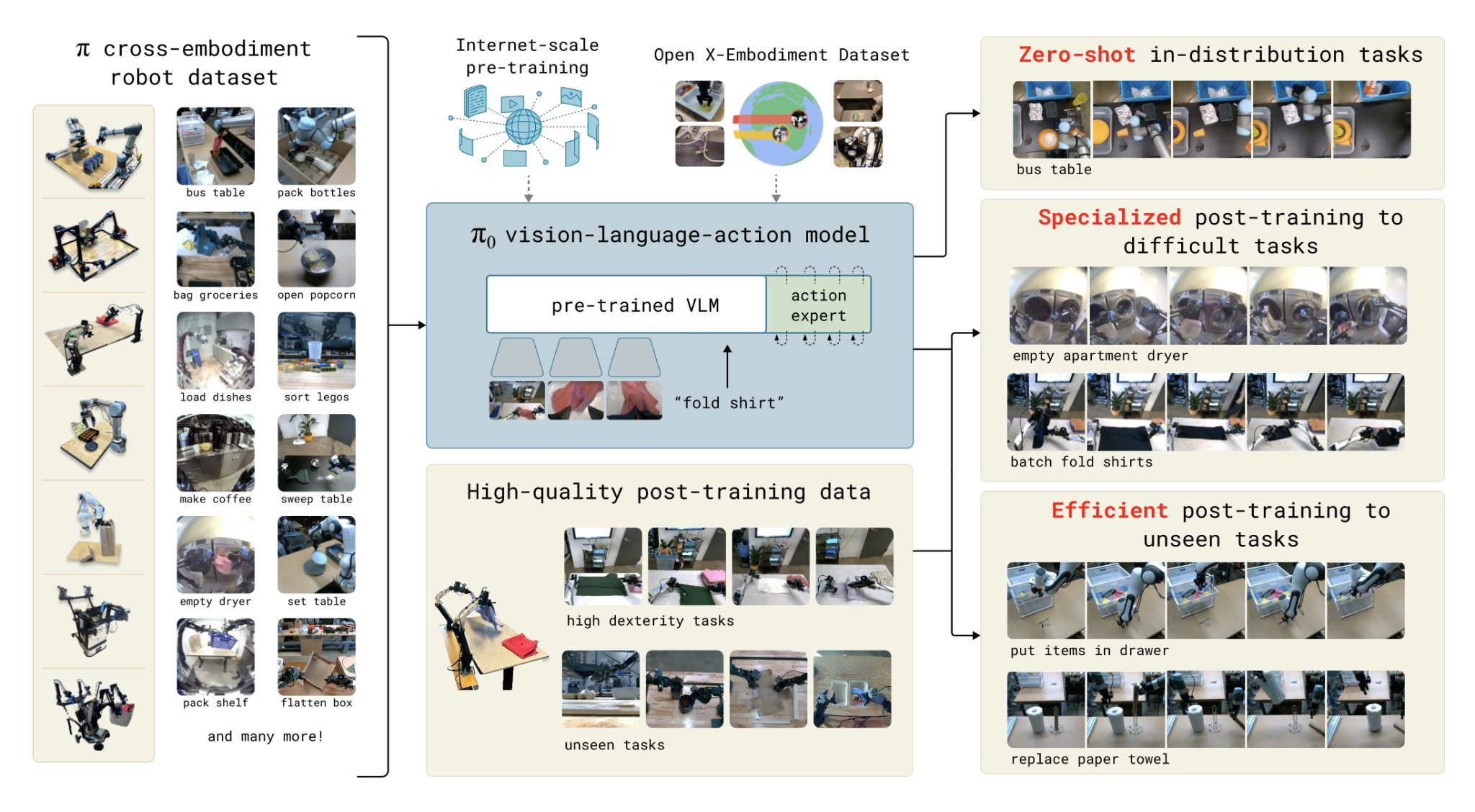
그림 1 오픈 VLA 기본 아키텍처 오픈 VLA는 로봇 파운데이션 모델 연구의 공용 기준선을 제공한 것으로 자연어 처리의 BERT/GPT 이전 단계에 해당한다고 볼 수 있다. 다만 월드 모델이 없는 피지컬 AI 접근으로 명시적인 물리 시뮬레이터, 동역학 모델, 상태 전이 함수를 포함하지 않는다. VLA 모델의 발전 새롭게 등장한 VLA 모델은 모델 크기를 키우는 방식 대신 아키텍처 자체를 바꾸는 방식으로 전환을 꾀했으며, 로봇의 행동을 본질적으로 어떻게 모델링해야 하는가에 대한 질문을 던졌다. 먼저 플로우 매칭(Flow Matching) 기반 정책을 통해 행동 자체를 어떻게 잘 생성할 것인가에 대한 연구를 했던 파이제로(π 0) 모델, 로봇의 지능 구조를 어떻게 나눠야 하는가에 대한 코그니션-액션 구조를 분리한 CogACT 모델, 그리고 로봇 VM 모델이 등장했다. 파이제로는 피지컬 인텔리전스가 제시한 것으로 기존 VLA 모델이 가진 구조적 한계, 특히 장기 계획, 반사실적 평가, 다단계 안정성을 해결하려는 시도이다.2) 핵심 문제의식은 정책만으로는 충분하지 않으며 행동은 생성되어야 하고 그 전에 검토해야 한다는 것에서 출발했다. 파이제로는 디퓨전 액션 모델을 통해 하나의 “답”이 아니라 여러 가능한 행동 경로를 확보해 이후 단계에서 선별과 검증을 하겠다는 방식이다. 고전적 의미의 심볼릭 플래너를 사용하지 않지만 행동 후보가 물리적으로 말이 되는 것인가를 내부적으로 걸러낸다.
그림 2 파이 제로 아키텍처 개념도 이를 통해 단기 오차에 덜 민감하고 수 초 단위 반응이 아닌 수십 단계 연속 행동의 안정성을 확보해서 긴 시간에 대응할 수 있게 했다. 파이 제로는 완전한 월드 모델이 아니지만 반사실적 행동 후보나 물리적으로 불가능한 행동을 제거함으로써 월드 모델에 대한 완충재 역할을 할 수 있다. 한 마디로 행동을 직접 예측하는 대신 ‘생성·검토·선택’하는 확률적 정책으로, VLA가 넘지 못한 장기적 피지컬 지능의 문턱을 낮춘 모델이다. 모델은 먼저 로봇이 관측한 시각 정보(RGB/Depth)와 인간이 제공한 자연어 태스크 지시를 입력으로 받아, 현재 환경과 수행해야 할 목표를 동시에 조건으로 설정한다. 이 관측 정보와 지시는 하나의 잠재 표현으로 결합되며, 이 표현은 객체의 정체를 인식하는데 그치지 않고 어떤 행동이 가능한지를 중심으로 압축된다; 명시적인 물리 시뮬레이터나 월드 모델은 없지만, 데이터 학습을 통해 물리적 제약과 상식이 잠재적으로 반영된 상태 공간을 형성한다. 이 잠재 상태를 조건으로, 모델은 무작위 초기 노이즈에서 출발하여 반복적인 노이즈 제거 과정을 거치며, 단일 행동이 아니라 시간상으로 연속된 행동 시퀀스를 점진적으로 생성한다. 생성된 행동 시퀀스 중에서 최종 단계 혹은 중간 단계의 행동이 선택되어, 저수준 제어 인터페이스를 통해 실제 로봇이 실행한다. 파이제로의 플로우 매칭 기법이란 확산 기반 행동 생성을 연속적인 결정론적 흐름(플로우)으로 만들어 행동 시퀀스를 안정적이고 효율적으로 생성하기 위한 방식을 의미한다. 플로우 매칭은 한 번의 결정이 아니라 연속적인 수정 과정이기 때문에 초기에는 거칠게 나와도 점점 물리적으로 그럴듯한 행동으로 생성하고 충돌이나 불안정한 방향은 자연스럽게 배제함으로써 명시적 월드 모델 없이 계획 수립에 가까운 효과를 만든다. 다음으로는 코그액트(CogACT)가 있다. 코그액트는 행동 이전에 행동에 대해 생각하는 계층을 명시적으로 두자는 발상에서 칭화대학, 마이크로소프트 연구소, 중국과학기술대학 등의 연구진이 제안했다.3) 기존 VLA 계열이 즉각적인 반응에는 강하지만 장기 계획, 실패복구, 반사실적 검토가 취약하다는 점이 있고, 월드 모델 접근은 강력하지만 학습 비용이 높고, 실제 로봇 적용까지는 간극이 크다는 판단에서 연구가 이루어졌다. 한 마디로 코그액트는 인지적 논증(Cognitive Reasoning)과 행동 실행(Action)을 분리 연결한 계층형 피지컬 AI 아키텍처라고 말할 수 있다. 다시 말해 생각하는 모델과 움직이는 모델을 의도적으로 분리한 것이다. 인지 레이어는 LLM/리즈닝 트랜스포머로 구현하며 태스크 해석(goal parsing), 과업 분해 (task decomposition), 순서 결정 (ordering), 실패 시 재계획 (replanning), 제약 조건 명시화 등을 담당한다. 이 레이어의 출력은 행동 그 자체가 아니라 행동을 어떻게 해야 하는가에 대한 구조적 지침이다. 예를 들어 ‘먼저 컵을 비운다 → 다음에 들어 올린다’던가 ‘잡을 수 없으면 위치를 바꾼다’ 같은 지침을 말한다. 다음 계층은 전형적인 VLA/확산 정책 형식으로, 인지 레이어의 지시를 조건으로 받아서 주어진 맥락에서 즉각적이고 안정적으로 잘 움직이도록 설계된 실행 전용 정책을 말한다. 예를 들어 입력으로 현재 카메라 이미지, 로봇의 내부 상태 (관절 각도, 속도 등), 상위 인지 레이어가 내려준 지시를 받으면, 다음 순간에 취할 연속 제어 명령 즉, 최종 이펙터 위치 변화, 관절 토크와 속도, 그리퍼 개폐 정도를 출력으로 보낸다. 하위 액션 레이어는 항상 시각 입력을 기준으로 반응하며 상위 추론이 개입하기엔 너무 빠르고 낮은 수준이 필요한 미세한 변화에 대응하는 것이고 인간의 소뇌에 해당한다고 볼 수 있다. 또한 낮은 수준의 연속적 제어가 중요한 이유는 위치를 살짝 바꾸거나, 힘을 약간 줄이는 것, 각도를 부드럽게 조정하는 것은 연속적인 제어를 통해서 하는 것이 더 낫기 때문이다. 하위 계층은 자체적인 장기 계획을 하지 않는데 다음 1–3초, 또는 다음 몇 스텝만을 보고 행동하는 것이지, 전체 작업의 순서 설계, 실패 후 전략 변경, 목표 재정의 등은 관여하지 않는다. 코그액트는 실패 원인 분석 용이, 상위 추론만 교체 가능, 하위 제어 재사용 가능 같은 구조적 장점을 갖고 있으며, 이를 통해 포스트-VLA 아키텍처를 지향하고, LLM 리즈닝을 피지컬 AI에 도입했으며, 월드 모델로 가는 중간 단계에 해당하는 모델이다. 또 다른 접근 방식으로는 로보VLM이 있는데, 이는 로봇 세계에 특화된 시각–언어 표현을 학습하여, 로봇 행동을 직접 또는 간접적으로 지원하는 비전–언어 기반 로봇 모델이다. 로보VLM은 정책 자체가 아니라 정책을 가능하게 하는 인지·표현 계층에 가깝다고 봐야 하는데, 시각-언어 표현 안에 행동 가능성을 포함하고 있다. 이를 위해 학습할 때 보이는 것이 아니라 할 수 있는 것 중심의 표현을 학습하도록 한다. 따라서 시각 토큰은 객체 분류용이 아니라 조작 관점의 시각 특징을 강조한다. 따라서 로보VLM은 동역학 시뮬레이션을 하지 않지만 행동 가능성에 대한 정적 지식을 제공하기 때문에 월드 모델의 보조재 역할 또는 월드 모델 학습의 표현 기반으로 활용할 수 있다. 한마디로 로보VLM은 움직이기 전의 이해를 담당한다고 보면 된다. 대형 멀티모달 추론 모델과 VLA의 결합 기존 VLA는 즉각적인 반응에는 강하지만 장기 목표 유지, 계획, 반사실 평가가 약하다는 점을 해결하기 위해 구글 딥마인드는 ‘대형 멀티모달 추론 모델(제미나이)을 상위 인지 및 계획 엔진으로 두고, VLA 정책을 실행 계층으로 결합한 계층형 피지컬 AI 시스템인 제미나이-로보틱스를 발표했다.4) 딥마인드의 판단은 VLA만 키우는 것은 한계가 있고 추론과 계획은 언어-추론 모델이 맞고 실행은 VLA가 맡아야 한다는 것이다. 제미나이 로보틱스 1.5는 VLA인 제미나이 로보틱스(GR) 1.5와 첨단 VLM인 제미나이 로보틱스 1.5-ER (GR_ER) 두 가지로 이루어졌다. GR-ER은 첨단의 체화 논증 기능이 있는 VLM이라고 한다. GR-ER 1.5는 보고(Vision), 지시(Language)를 받아 계획·판단·공간 추론·진행 상태 추정을 수행하고, 실행을 오케스트레이션 하는 모델이다. GR-ER은 행동을 직접 하는 것이 아니라 로봇에 필요한 인지 작업을 한다. 이번에 현대차가 발표한 보스턴 다이나믹스의 아틀라스 로봇이 활용하는 것이 바로 제미나이 로보틱스 VLA라는 점이 이 모델 아키텍처에 관심을 갖게 하는 이유이다. 자연어 지시를 하위 과업으로 분해하고, 장면을 보고 공간적/시각적 추론(무게, 크기, 집기 가능성 등)을 수행하며, 과업 계획, 진행도 추정, 실패와 변경을 감지, 필요하면 외부 도구(검색 같은)로 정보를 보강해 규칙이나 제약을 반영한다. 그리고 그 결과를 단계별 자연어로 VLA에 전달한다. 제미나이 로보틱스 1.5의 VLA 부분은 GR-ER이 내린 ‘이번 스텝의 지시’와 현재 시각 상태를 받아서 연속 제어를 생성해 로봇을 구동한다. 실행 중 환경 변화에 미세 조정, 그리퍼/팔 제어와 같은 실시간 대응을 하며, 실행 결과/관찰을 다시 GR-ER 쪽으로 넘겨 다음 스텝 의사결정을 돕는 에이전트 루프 방식으로 작동한다. 그러나 VLA 파트가 “생각을 전혀 안 하는” 모델이 아니라, 실행 안정성과 다단계 수행을 위해 제한적 내부 사고를 포함할 수 있다. 다만 ‘장기적 과업 분해/오케스트레이션의 주도권’은 GR-ER 쪽에 더 크게 배치된 설계이다.
그림 3 제미나이 로보틱스 1.5의 구성 코그액트처럼 상위의 제미나이는 비전과 언어를 입력으로 받아서 태스크 해석, 단계 분해, 실패 감지 및 재계획, 도구/행동 선택과 같은 내용과 같은 ‘무엇을 해야 하는가’만 결정하지 액션을 직접 내 놓는 것이 아니다. 하위의 VLA 기능이 제미나이가 내려준 지시(조건)에 따라 그리퍼, 조인트, 엔드 이펙터에 대한 연속 제어를 출력으로 내놓는다. 구글은 전통적 물리 시뮬레이터인 월드 모델을 전면 배치하지 않고 언어와 추론 기반의 구조적 예측으로 보완하는 것인데, 이는 월드 모델의 일부 기능을 추론으로 흡수하는 것이다. 이런 접근에 비해 엔비디아는 VLA 접근을 하나의 단일 모델이 아니라 플랫폼·스택 관점에서 본다. 핵심은 “VLA를 실행 정책으로 두고, 그 위·아래를 시뮬레이션·데이터·가속으로 감싸는 구조”이다. 다시 말해 엔비디아의 VLA 전략은 ‘단일 로봇 모델’이 아니라, VLA 정책이 대규모 데이터·시뮬레이션·가속 위에서 빠르게 학습·검증·배포되도록 설계된 풀스택 피지컬 AI 체계이다. 엔비디아가 생각하는 전제는 다음과 같다.
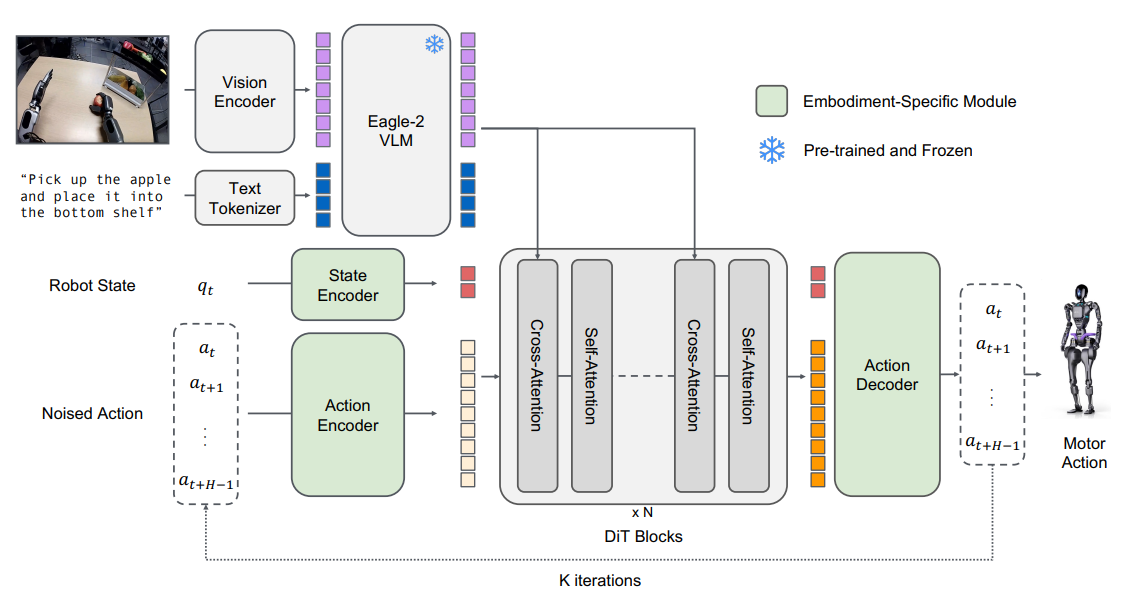
즉 좋은 VLA 하나보다 VLA가 자라는 환경이 중요하다고 판단했다. 따라서 VLA를 아래와 같이 중간 계층에 위치하는 것으로 본다. 그림 4 엔비디아의 VLA를 위한 계층 구조 엔비디아가 공개한 그루트(GR00T)는 엔비디아식 VLA의 대표적 사례이다. 이번 CES에서는 자율 주행을 위한 알파마요를 소개했는데 이는 다음 글을 통해서 설명하도록 하겠다. 그루트는 단독 모델이 아니라 아이작(Isaac), 옴니버스, GPU 가속을 전제로 결합된 기능이다. 하부 인프라에 있는 아이작 심(Sim)은 물리적으로 의미 있는 로봇 시뮬레이션이다. 여기에서는 센서·마찰·충돌·지연 모델링을 할 수 있다. 옴니버스는 디지털 트윈이며 합성 데이터를 생성한다. 엔비디아는 VLA는 정책이지 월드 모델이 아니기 때문에 월드 모델을 VLA 안에 넣기보다는 아이작 심이 외부 월드 모델 역할을 수행한다. 즉, VLA는 실행에 집중하고 예측과 검증은 시뮬레이션에서 반복한다. 이 부분이 구글이나 피지컬 인텔리전스 계열과 다른 철학이다. 엔비디아 VLA에게 언어는 태스크 지정, 객체 참조, 조건 부여를 하는 역할이며 장기 추론이나 재계획은 상위 LLM 계층 또는 시스템 로직에서 담당하도록 분리한다. 또한 엔비디아는 GPU 대규모 병렬화를 기반으로 수천-수만 에피소드를 동시에 시뮬레이션하고, 확산 정책과 VLA 학습을 가속하도록 해서 스케일링으로 불확실성을 누르는 전략을 취하고 있다. 이는 로봇을 다음 GPU 수요처로 만들겠다는 전략과 모델 경쟁이 아닌 플랫폼 락인 전략을 취한다는 의미이다. 그림 5 그루트 N1 모델 아키텍처 엔비디아는 월드 모델을 ‘학습해야 할 신경망’이 아니라, ‘이미 검증된 물리 및 시뮬레이션 인프라로 제공해야 할 시스템’으로 보기 때문에 모델 안에 넣지 않는다. 즉, 월드 모델의 책임을 신경망이 아니라 플랫폼이 진다는 선택을 했다. 그래서 다음 달에 소개할 코스모스라는 월드 파운데이션 모델을 만들어서 옴니버스-코스모스-시뮬레이터-VLA 구조를 완성했다. 나가면서 지금까지 우리는 피지컬 AI를 위한 AI 모델의 발전을 주로 VLA 기술의 발전과 이를 플랫폼으로 접근하는 엔비디아 전략까지 살펴봤다. 각 모델이 추구하는 장점과 VLA이 수행하는 진짜 업무는 무엇이고, 월드 모델은 어디에 있으며 기본 전략의 철학이 무엇인지를 제대로 알 수 있어야 우리나라의 피지컬 AI를 위한 연구개발 전략을 세울 수 있다. 다음 글에서는 월드 모델, 월드 파운데이션 모델과 피지컬 AI로 접근하는 규모 있는 기업의 전략을 좀 더 깊이 있게 살펴볼 예정이다. 참고문헌 1) Moo Jin Kim, et. al., “OpenVLA: An Open-Source Vision-Language-Action Model,” arXiv, Sep 5, 2024 2) 파이 제로에 대한 포괄적인 소개와 데모는 피지컬 인텔리전스 웹사이트에서 볼 수 있다. https://www.pi.website/blog/pi0 3) Qixiu Li, et. al., “CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation,” arXiv, Nov 29, 2024 4) Gemini Robotics Team, “Gemini Robotics 1.5: Pushing the Frontier of Generalist Robots with Advanced Embodied Reasoning, Thinking, and Motion Transfer,” arXiv, Nov 28, 2025
이슈리포트 2026-01호.pdf (1 MB)
|
||